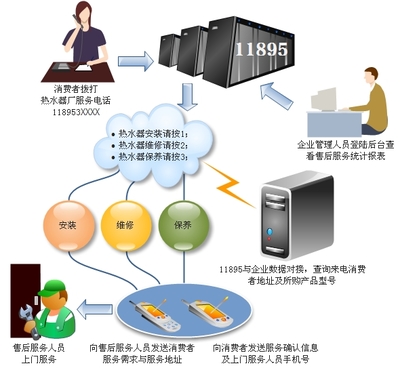
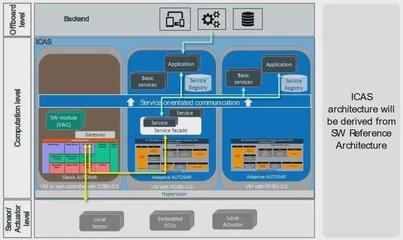
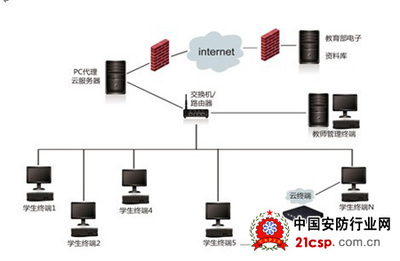
在当今数据爆炸的时代,企业每天需要处理的数据量已经从GB级跃升至TB甚至PB级。如何高效、可靠地处理这些海量数据,成为技术领域的一个核心挑战。从单机的并发编程到跨机器的分布式系统,数据处理技术经历了一场深刻的演进,每一次跃迁都是为了突破性能、可靠性与扩展性的极限。
并发编程:榨干单机性能的利器
当数据量尚未达到“海量”级别,或者业务对实时性要求极高时,充分利用单台服务器的计算资源是最直接的选择。并发编程正是在这种背景下成为关键技术。通过多线程、多进程或异步I/O等模型,程序可以同时执行多个任务,从而显著提高CPU利用率和系统吞吐量。
例如,一个网络服务器使用线程池处理并发的用户请求;一个数据分析脚本使用多进程并行处理多个文件。Java的并发包(java.util.concurrent)、Python的asyncio库、Go语言的goroutine都是这一领域的杰出代表。它们帮助开发者在单机环境下,构建出高响应、高吞吐的数据处理管道。
并发编程有其物理上限。单台服务器的CPU核心数、内存容量和磁盘I/O终究是有限的。当数据量增长到单机无法在可接受时间内处理完毕时,技术的焦点便从“纵向扩展”(增强单机能力)转向了“横向扩展”(增加机器数量)。
分布式系统:横向扩展的艺术
分布式系统的核心思想是将一个庞大的计算任务或海量数据集,分解成多个子任务或数据分片,并将其分发到由网络连接的多台计算机(节点)上并行执行,最后将结果汇总。这解决了单机在存储和算力上的根本性瓶颈。
- 分布式计算框架:以Apache Hadoop和Apache Spark为代表。Hadoop的MapReduce编程模型将计算抽象为Map(映射)和Reduce(归约)两个阶段,适合处理离线批量数据。Spark则通过内存计算和更丰富的算子(如转换、行动),在迭代计算和流处理上性能更优,实现了批流一体。
- 分布式存储系统:海量数据必须要有可靠的“家”。像HDFS(Hadoop Distributed File System)、Google File System(GFS)以及云时代的对象存储(如AWS S3),它们将文件切块并在多个节点上存储副本,既提供了巨大的存储空间,也通过冗余保证了数据的高可用性。
- 分布式协调与资源管理:管理成百上千台机器是一个复杂问题。ZooKeeper提供了可靠的分布式协调服务(如配置管理、命名服务、分布式锁)。YARN和Kubernetes则作为集群资源管理器,负责在分布式集群中调度计算任务,高效利用所有节点的资源。
构建分布式系统带来了新的挑战:网络延迟与故障成为常态、数据一致性难以保证、系统状态监控和调试变得异常复杂。CAP理论(一致性、可用性、分区容错性不可兼得)指导着我们在设计时做出权衡。
技术栈融合:应对现代数据洪流
现代海量数据处理架构,往往是并发编程与分布式系统技术的深度融合。
- Lambda/Kappa架构:在流处理领域,Lambda架构同时维护批处理和流处理两条管道,以平衡延迟与准确性。而Kappa架构主张全部用流处理来实现,简化了系统复杂度。Apache Flink作为新一代流处理引擎,以其高吞吐、低延迟和精确的状态管理,成为实现这些架构的理想选择。
- 云原生与Serverless:云计算平台将分布式系统的复杂性进一步封装。通过容器化、微服务和Serverless计算(如AWS Lambda),开发者可以更专注于业务逻辑,而无需深度管理集群。数据湖、湖仓一体等概念,也在云上提供了弹性、统一的海量数据存储与分析平台。
- 并发与分布式的交织:在一个分布式数据处理任务中,每个工作节点内部依然会大量使用并发编程技术来最大化自身性能。例如,一个Spark Executor会利用多线程并行执行多个Task。
###
从并发编程到分布式系统,海量数据处理的演进之路,是一部不断突破边界、化解复杂性的历史。并发编程是高效利用单机资源的基石,而分布式系统则是应对数据规模无限增长的必由之路。随着人工智能、物联网产生更庞大的数据集,处理技术将继续向更智能的自动化调度、更统一的批流处理、以及更极致的性能与成本优化方向发展。理解从并发到分布式的技术全景,是每一位数据工程师和系统架构师驾驭数据洪流的必备素养。